Temporary holds: Leveraging machine learning models to reduce fraud
In order to build even stronger defences against fraud while preserving customer experience, we transitioned from rules-based pre-authorization to an ML model. This led to a decrease in losses and improved user experience.
Introduction
Careem’s Everything App simplifies the lives of millions of people in the region with a delightful and secure user experience. The platform now offers over a dozen digital services including ride-hailing, with over 1 billion rides completed across the region.
The rapid growth of the Everything App has attracted the attention of fraudsters, like most large technology companies. This makes the enhancement of security measures a top priority for us.
Part of our journey of improving security meant transitioning from a traditional rule-based approach to a more sophisticated and adaptive machine learning model for pre-authorisation. Pre-authorisation is a mechanism designed to mitigate potential fraud risks. This transition, though challenging, was crucial in refining our fraud prevention approach and enhancing user experience.
In this post, we’ll discuss the nuances of pre-authorisation, the limitations of relying solely on rules, and the challenges and benefits associated with implementing machine learning models. We’ll also provide a glimpse into our model development and deployment phases, as well as the tangible improvements we have witnessed in increasing precision and reducing user complaints. We hope that our experiences and learnings offer valuable perspectives and inspire innovative thinking in addressing fraud in the digital landscape.
Pre-authorisation

One of the most common issues encountered in ride-hailing is when a customer has a card attached to their account, books a ride, and completes it, but the company is unable to receive payment for the trip. Payment failures can be caused by various reasons, such as insufficient funds in the card balance, a stolen card, or even a fake card. One solution to this problem is pre-authorisation.
Pre-authorisation is a temporary hold placed on a customer’s credit card, which lasts for a predefined duration or until a full settlement is made. This mechanism is commonly used to prevent potential fraud.
However, applying pre-authorisation indiscriminately to all users can negatively impact the user experience: some people may not like the idea of pre-authorisation by itself, considering it a sign of mistrust; sometimes lifting the hold takes several days which inconveniences people. To address this, we have a set of controls (rules) that determine when pre-authorisation should be initiated.
Some rules have straightforward conditions, such as “if X condition is met, then initiate pre-authorisation”. Others may involve multiple checks and exclusions.
We have an internal system for creating, managing, and deploying these rules. This system ensures that we can complete the process from rule conceptualization to live application within minutes.
However, rule-based methods have limitations:
- Managing a large number of rules can be complex.
- Rules yield definitive outcomes, whereas machine learning models offer probabilistic results.
- There is a risk of rules being reverse-engineered. For example, we once deployed a rule stating “if value < N, then block user”. Although it initially worked well, we observed an increase in fraudulent activities when accounts realised the threshold and adjusted their actions to just above it, at N + 1.

In contrast, while ML models have their own limitations, they also offer certain advantages. Specifically, ML models provide greater adaptability across new dimensions and regions and allow for more precise management of the precision-recall trade-off through threshold adjustments.
Challenges of building the model

Before developing an ML model, it is important to understand the potential challenges and inherent limitations.
The most important metrics for businesses to consider are Precision and Recall. Precision measures the relevance of pre-authorisations, while Recall assesses the model’s coverage of fraudulent cases. Increasing Recall helps minimize financial losses, while higher Precision reduces customer complaints. In technical terms, Precision represents the fraction of relevant instances among the retrieved instances, while Recall represents the fraction of relevant instances that were retrieved.
Our controls offer three potential transaction outcomes: approval, denial, or pre-authorisation issuance. The challenge arises when trying to determine the true metrics of our controls. For example, if we deny a transaction, it is difficult to determine whether it was fraudulent or genuine.
In cases where a model suggests approval or pre-authorisation, but an overriding rule denies the transaction, accurate model performance assessment becomes obscured. Remedies for this include comparing the system’s performance before and after model implementation or splitting traffic between the previous and new models.
Our project had strict business constraints: the model needed to have a Recall of at least 0.9 while simultaneously maximizing precision. This highlights the importance of calibrating the model’s threshold.
The model’s real-time responsiveness is crucial for providing a seamless user experience during ride bookings. This requires an efficient and fast model, placing additional emphasis on model optimisation.
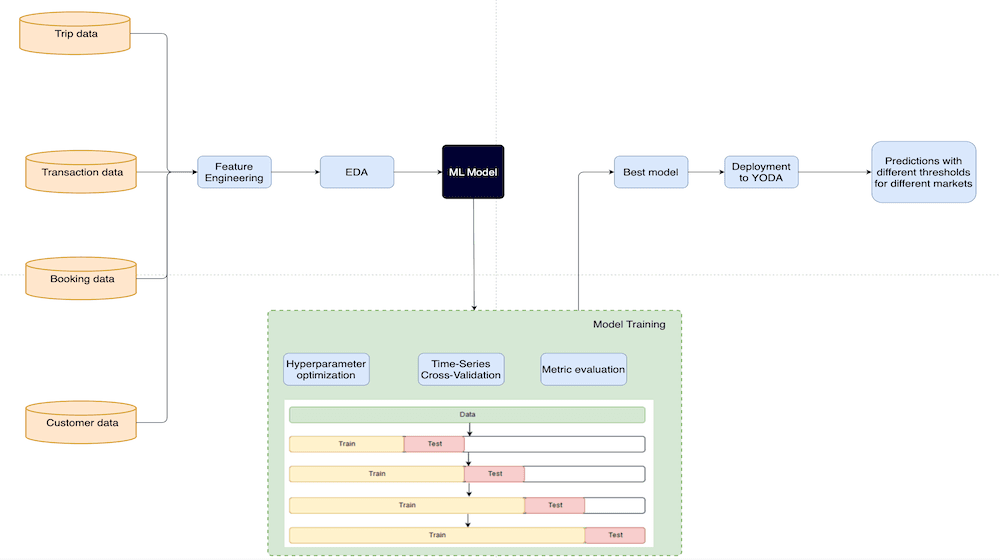
Model development
In machine learning competitions, participants often use a huge number of features, aiming to achieve top performance on a fixed, unseen dataset. However, in real-world applications like ours, the primary objective is to create a good, consistent model that can make real-time predictions.
Data Preparation
Even though companies like Careem have collected huge datasets over time, it is important not to indiscriminately feed all available data into the model. Here’s why:
- Using all available historical data is not very useful because recent behaviour is more important than actions from several years ago.
- It is not necessary to use all customer information in each model. It is better to identify common fraudulent behaviours and create features based on them. Sometimes, a single insightful feature can outperform dozens of generic ones.
- Not all post-event data is accessible in real-time. For example, we may have data on the final trip price after a journey, but this information is not available when making predictions.
- The same data can be stored in multiple places and different formats, from raw user trip logs to aggregated data tables. Although they should technically match, discrepancies can occur. It is crucial to verify and ensure the integrity of the data.
Model training

In the current state of machine learning, it can be tempting to utilize complex solutions like neural networks. However, these can be difficult to tune, and deploy, and may not consistently provide optimal performance on tabular data. While anomaly detection models like Isolation Forest or one-class classification may seem appealing, traditional supervised methods tend to work better when there is an abundance of labeled data.
As a result, many industry professionals prefer gradient boosting models such as XGBoost, LGBoost, Catboost, and Pyboost. These models are easy to train, perform efficiently, and deliver prompt results. For this particular use case, we have chosen to use Catboost due to its exceptional handling of categorical variables.
However, selecting a model is just the first step. Ensuring its reliability requires a robust validation process. While there are various validation strategies available, such as group k-fold based on data groups or stratified k-fold based on classes, the time-sensitive nature of our data led us to opt for time-based validation. This approach involves training on several weeks of data and predicting the subsequent weeks. It also employs a rolling validation technique, using shifting windows for continuous training and validation.
This validation approach also allows for retrospective testing of the model’s performance against past data, thereby further enhancing its reliability.
Preparing for model deployment
One essential requirement is that our model operates almost in real-time. This speed doesn’t allow for on-the-spot complex calculations or data queries each time we need to make a prediction.
To explain how we achieve this, let me give an example. Suppose we want to track how many “special” trips a user has taken over the past three weeks. A basic SQL query might look like:
SELECT user, COUNT(*)
FROM user_trips
WHERE trip_type = "special"
GROUP BY user
This works when gathering training data. However, for real-time values, we tweak it slightly:
SELECT user, COUNT(*)
FROM user_trips
WHERE trip_type = "special"
AND day = {date}
GROUP BY user
This modification lets us collect daily data for each user. Then, it’s a straightforward task to calculate the count of “special” trips for any time span, such as the last 1, 3, 7, or 21 days.
Our specialized internal system streamlines this, ensuring we always have up-to-date feature values for immediate predictions.
Another vital step is aligning our training and production data. Checking for discrepancies, such as string formatting differences or varying default missing values, is crucial.
Model deployment

After completing data preparation and configuring the model, the next step is deployment using our in-house platform, YODA. This platform allows for writing flexible code to run models, integration with AWS, and the creation of endpoints. These endpoints enable us to input data and obtain model predictions.
However, before any model is put into production, it needs to be tested. In our case, we used a “shadow mode” approach. This means that the model makes predictions for real trips but does not take any action based on those predictions. This approach introduces complexities when measuring metrics, such as instances where the model suggests pre-authorisation but other controls decline the transaction. In such cases, it can be challenging to determine the actual accuracy of the prediction.
Once we have confidence in the performance of our model, we gradually transition it to live operations.
Conclusions
Transitioning Careem from rule-based methods to adopting machine learning models for pre-authorisation led to limitations as well as adaptability and precision advantages.
Real-time responsiveness and the balance of security with user experience is key. The results have been promising, with a 60% increase in precision and a reduction in customer complaints, demonstrating the effectiveness of our new approach.
However, our work is far from complete. The constantly evolving nature of fraud requires us to remain vigilant, continuously improving and adapting our methods to counter new threats. We are dedicated to learning and evolving to ensure the security of our platform and maintain the trust of our users and we hope that our journey provides valuable insights and sparks discussions on developing advanced strategies for fraud prevention.
About the author
Andrei Lukianenko is a Data Scientist working in Careem’s Integrity team. In his free time, he studies foreign languages, reads fantasy books, and writes reviews on modern AI papers.
Check out another article from our Careem Engineering team here.


